
Hyperplane คือ subspace ที่มีจำนวน dimension น้อยกว่าสภาพแวดล้อมอยู่ 1 dimension
รูปแบบทั่วไปของสมการเส้นตรงในวิชาพีชคณิตที่มองเส้นตรงในรูปแบบของความสัมพันธ์ระหว่างตัวแปร คือ
\[ \bf y = ax + b \dashrightarrow (1) \]
ถ้าใน calculus จะมองในรูปแบบของฟังก์ชั่น จะเขียนในรูปแบบคือ
\[\bf f(x) = ax + b \dashrightarrow (2) \]
จาก (1) เราสามารถเขียนในรูปแบบที่ไม่มีตัวแปร y อยู่ได้ โดยแทน y ด้วย \( x_2 \) และ x แทนที่ด้วย \( x_1\) จะได้เป็น
และถ้ากำหนดให้ \( W = \begin{bmatrix}a & -1\end{bmatrix} , X = \begin{bmatrix} x_1 \\ x_2 \end{bmatrix} \) แล้ว เราอาจเขียนสมการเส้นตรงในรูปแบบของ Matrix ได้แบบนี้
พิจารณาอีกครั้ง ถ้ากำหนดให้ \( W = \begin{bmatrix}w_1 & w_2 \end{bmatrix}, X = \begin{bmatrix}x \\ y \end{bmatrix}\) แล้วนำแทนใน (5) จะได้
\[ \bf x_2 = ax_1 + b \dashrightarrow (3)\]
\[ \bf ax_1 -x_2 + b = 0 \dashrightarrow (4)\]
และถ้ากำหนดให้ \( W = \begin{bmatrix}a & -1\end{bmatrix} , X = \begin{bmatrix} x_1 \\ x_2 \end{bmatrix} \) แล้ว เราอาจเขียนสมการเส้นตรงในรูปแบบของ Matrix ได้แบบนี้
\( \bf W \cdot X + b = 0 \dashrightarrow (5) \)
ข้อดีของการเขียนสมการเส้นตรงในรูปแบบ (5) คือ สามารถกำหนดจำนวน dimension ให้กับ Matrix ได้ตามที่ต้องการ
พิจารณาอีกครั้ง ถ้ากำหนดให้ \( W = \begin{bmatrix}w_1 & w_2 \end{bmatrix}, X = \begin{bmatrix}x \\ y \end{bmatrix}\) แล้วนำแทนใน (5) จะได้
\[ \begin{bmatrix}w_1 & w_2 \end{bmatrix} \cdot \begin{bmatrix}x \\ y \end{bmatrix} + b = 0\]
\[ w_1 x +w_2y + b = 0 \]
\[ w_2y = -w_1 x -b \]
\[ \therefore y = \frac{-w_1}{w_2}x - \frac{b}{w_2} \dashrightarrow(6) \]
เมื่อนำไปเทียบกับ \( \bf \large y = ax + c \) จะได้ slope คือ \(\frac{-w_1}{w_2} \) และจุดตัดแกน y คือ \( - \frac{b}{w_2} \)
\[ w_2y = -w_1 x -b \]
\[ \therefore y = \frac{-w_1}{w_2}x - \frac{b}{w_2} \dashrightarrow(6) \]
เมื่อนำไปเทียบกับ \( \bf \large y = ax + c \) จะได้ slope คือ \(\frac{-w_1}{w_2} \) และจุดตัดแกน y คือ \( - \frac{b}{w_2} \)
ดูตัวอย่าง ถ้าเรามีข้อมูลคู่อันดับอยู่ชุดหนึ่งดังนี้
\( data = [(1,3),(2,5),(2,7),(4,4),(4,6),(4,8),(4,10),(7,5),(7,10),(8,3),(8,7),(9,6),(9,7),(10,10)]\)
นำไป plot จะได้ดังรูปที่ 1
 |
| รูปที่ 1 |
พิจารณาด้วยสายตาเห็นได้ว่าข้อมูลมีแนวโน้มของการรวมกลุ่มกันเป็นสองกลุ่ม หากเราทดลองลากเส้นตรงหนึ่งเส้นเพื่อแบ่งกลุ่มข้อมูล อาจได้ดังรูปที่ 2
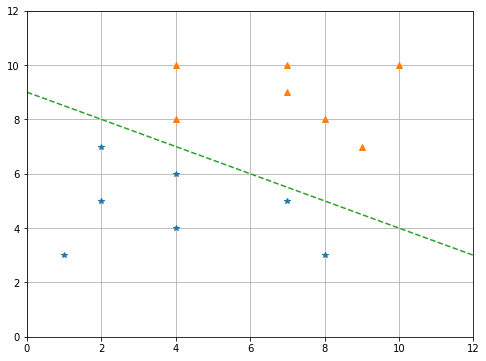 |
| รูปที่ 2 |
คำนวณหาสมการเส้นตรงได้เป็น
\[ \bf y = -0.4x + 9 \]
\[ \bf y + 0.4x - 9 = 0 \]
นำไปเทียบกับ (6) จะได้
\( \bf W = \begin{bmatrix} 0.4 & 1.0\end{bmatrix} , X = \begin{bmatrix} x \\ y\end{bmatrix} \) และ \( \bf b = -9.0 \)
สมการที่ได้คือ\[ W \cdot X - 9 = 0 \]
ในการแยกกลุ่มข้อมูล เพื่อให้รู้ว่าข้อมูลแต่ละชิ้นจะไปอยู่ในกลุ่มไหน เราจำเป็นต้องกำหนด function ขึ้นมาใหม่อีกหนึ่ง เรียกว่า hypothesis function โดยที่
\( \bf h(x_i) =\begin{cases}1 & \text{if } W \cdot X - 9 \geq 0 \\-1 & \text{if }W \cdot X -9 < 0\end{cases} \)
จะเห็นได้ว่าเรากำหนดค่าของ \(h(x_i) \) มีเพียงสองค่าคือ 1,-1 จึงเหมือนกับเป็นการว่าคู่ลำดับใดควรอยู่กลุ่มไหนโดยดูจากค่าของ\(h(x_i) \) นั่นเอง
ขั้นตอนต่อไป เอาค่าของข้อมูลที่มีอยู่ (มองดูแล้วจะเห็นว่าข้อมูลอยู่ในรูป coordinate หรือ vector) มาแทนค่าลงในสมการเส้นตรง แล้วพิจารณาผลของ hypothesis function (h)
จากที่กล่าวมา จะเห็นได้ว่าการรวมกันระหว่าง linear equation กับ hypothesis function สามารถนำมาเพื่อแบ่งกลุ่มข้อมูล โดยที่เราจะเรียก hypothesis function ว่าเป็น Linear classifier เรียก linear equation ว่าเป็น Hyperplane equation
เพื่อลดความสับสนเราจะเติม 1 เข้าไปในข้างหน้าหรือท้ายของ \(\bf \large \vec x = (x_1,x_2,x_3,...,x_n) \) ซึ่งจะกลายเป็น \(\bf \large \vec x = (1,x_1,x_2,x_3,...,x_n) \) หรือ \(\bf \large \vec x = (x_1,x_2,x_3,...,x_n,1) \) เปลี่ยนสัญญลักษณ์เป็น \(\bf \large \hat{x} \)
และเติม b เข้าไปใน \( \vec w\) ในตำแหน่งเดียวกับ 1 ได้เป็น \(\bf \large \vec w = (b,w_1,w_2,w_3,...,w_n) \) หรือ \(\bf \large \vec w = (w_1,w_2,w_3,...,w_n,b) \) เปลี่ยนสัญญลักษณ์เป็น \(\bf \large \hat{w} \)
การเติมสมาชิกเข้าไปในลักษณะนี้ทำให้ค่าคงที่ในรูปแบบสมการ (1) นั้นหายไป ได้รูปใหม่ของสมการเป็น
และ hypothesis function :
| Data | \(W \cdot X - 9\) | \( h(x_i)\) |
|---|---|---|
| [1 3] | -5.6 | -1 |
| [2 5] | -3.2 | -1 |
| [2 7] | -1.2 | -1 |
| [4 4] | -3.4 | -1 |
| [4 6] | -1.4 | -1 |
| [7 5] | -1.2 | -1 |
| [8 3] | -2.8 | -1 |
| [4 8] | 0.6 | 1 |
| [ 4 10] | 2.6 | 1 |
| [ 7 10] | 3.8 | 1 |
| [7 9] | 2.8 | 1 |
| [8 8] | 2.2 | 1 |
| [9 7] | 1.6 | 1 |
| [10 10] | 5.0 | 1 |
จากที่กล่าวมา จะเห็นได้ว่าการรวมกันระหว่าง linear equation กับ hypothesis function สามารถนำมาเพื่อแบ่งกลุ่มข้อมูล โดยที่เราจะเรียก hypothesis function ว่าเป็น Linear classifier เรียก linear equation ว่าเป็น Hyperplane equation
เพื่อลดความสับสนเราจะเติม 1 เข้าไปในข้างหน้าหรือท้ายของ \(\bf \large \vec x = (x_1,x_2,x_3,...,x_n) \) ซึ่งจะกลายเป็น \(\bf \large \vec x = (1,x_1,x_2,x_3,...,x_n) \) หรือ \(\bf \large \vec x = (x_1,x_2,x_3,...,x_n,1) \) เปลี่ยนสัญญลักษณ์เป็น \(\bf \large \hat{x} \)
และเติม b เข้าไปใน \( \vec w\) ในตำแหน่งเดียวกับ 1 ได้เป็น \(\bf \large \vec w = (b,w_1,w_2,w_3,...,w_n) \) หรือ \(\bf \large \vec w = (w_1,w_2,w_3,...,w_n,b) \) เปลี่ยนสัญญลักษณ์เป็น \(\bf \large \hat{w} \)
การเติมสมาชิกเข้าไปในลักษณะนี้ทำให้ค่าคงที่ในรูปแบบสมการ (1) นั้นหายไป ได้รูปใหม่ของสมการเป็น
\[ \bf \hat{w} \cdot \hat{x} = 0\]
และ hypothesis function :
\[ \bf h(\hat{x_i}) = sign(\hat{w} \cdot \hat{x_i}) \dashrightarrow (7) \]
ความคิดเห็น
แสดงความคิดเห็น