
การวัดความเหมือนกันของข้อมูล
algorithm ที่ใช้การวัดความเหมือนของข้อมูลที่พบบ่อยแก่
- Euclidean
- Manhattan
- Minkowski
- Cosine Similarity
- Jaccard
Euclidean [1] เป็น algorithm ที่ใช้บ่อยมากที่สุด หากไม่มีการกำหนดชื่อ algorithm ไว้ มักจะอนุมานว่าใช้ตัวนี้ไว้ก่อน
\( d(x,y) =\sqrt[2]{\sum_{i=1}^n(x_i - y_i)^2} \)
Manhattan [2] อาจจะพบได้ในชื่ออื่น เช่น L1 distance, Taxicap
\( d(x,y) = \sum_{i=1}^n \mid x_i - y_i \mid\)
Minkowski [3] มองว่าเป็น general term ของทั้ง Euclidean และ Manhattan
\( d(x,y) = \left[ \sum_{i=1}^n \mid x_i - y_i \mid ^{p}\right] \frac {1}{p} \)
Cosine similarity [4]
เมื่อ vector u, v เป็น non-zero vector และทั้งสองทำมุมต่อกัน \( \theta \) องศาแล้ว

\( similarity = cos \theta \)
\( similarity = \frac{ \sum_{i=1}^n(x_iy_i)}{\sum_{i=1}^{n}x_i^2 \sum_{i=1}^{n}y_i^2}\)
\(\overrightarrow{u} = [2,3] \\ \overrightarrow{v} = [4,8] \\ \overrightarrow{s}=[10,11] \)
\( sim(u,v) = \frac {(2 \times 4) + (3 \times 8)}{(2^2 + 3^2)\times (4^2 + 8^2)} \)
\( sim(u,v) = 0.03\)
\( sim(v,s) = \frac {(4 \times 10) + (8 \times 11)}{(4^2 + 8^2)\times (10^2 + 11^2)} \)
\( sim(v,s) = 0.007\)
แสดงว่า \( \overrightarrow{v} \) ใกล้หรือเหมือนกับ \( \overrightarrow{s} \) มากกว่า \( \overrightarrow{u} \)
Jaccard similarity (Jaccard Index) [5]
ใช้หลักการของ Set มาช่วยพิจารณา บางครั้งจึงเรียกว่า Intersection over Union (IOU)
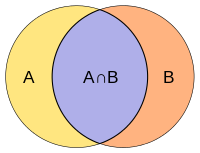

\( J(A,B) = \frac {\mid A \cap B \mid}{\mid A \cup B \mid} \)
ข้อดีของการใช้ Set คือ ข้อมูลไม่จำเป็นต้องมี dimension เท่ากันก็สามารถนำมาวัดความเหมือนได้ ยกตัวอย่าง



จะได้ว่า
\( J(A,B) = \frac {1}{8} = 0.125 \)
ตัวอย่าง
ถ้าในระบบฐานข้อมูลดอก Iris มีดังตารางข้างล่างนี้
| sepal length | sepal width | petal length | petal width | class |
| 6.3 | 3.3 | 6.0 | 2.5 | Iris-virginica |
| 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 6.9 | 3.1 | 4.9 | 1.5 | Iris-versicolor |
ในการเก็บข้อมูลภาคสนามครั้งหนึ่งได้ข้อมูลมาดังนี้ X = [4.6,3.1,1.5,0.2] มาใช้การวัดความเหมือนด้วย Euclidean เพื่อดูว่าดอกไม้ X ที่เก็บมาจะอยู่ใน class ใด
| Row | Distance |
| 1 | \( \sqrt[2]{ (4.6 - 6.3)^2 + (3.1 - 3.3)^2 +(1.5 - 6.0)^2 + (0.2 - 2.5)^2} = 5.33\) |
| 2 | \( \sqrt[2]{ (4.6 - 4.9)^2 + (3.1 - 3.0)^2 +(1.5 - 1.4)^2 + (0.2 - 0.2)^2} = 0.33\) |
| 3 | \( \sqrt[2]{ (4.6 - 6.9)^2 + (3.1 - 3.1)^2 +(1.5 - 4.9)^2 + (0.2 - 1.5)^2} = 4.33\) |
จากตารางจะเห็นว่าเมื่อเทียบกับ Iris-setosa (row 2) แล้ว จะได้ค่าระยะห่าง (distance) ต่ำที่สุด (ความเหมือนมีมาก) ดังนั้นดอก X ควรจัดอยู่ใน class Iris-setosa
--------------------------
เอกสารอ้างอิง
[1] https://en.wikipedia.org/wiki/Euclidean_distance
[2] https://en.wiktionary.org/wiki/Manhattan_distance
[3] https://en.wikipedia.org/wiki/Minkowski_distance
[4] https://en.wikipedia.org/wiki/Cosine_similarity
[5] https://en.wikipedia.org/wiki/Jaccard_index
ความคิดเห็น
แสดงความคิดเห็น