
หากมีจุดสามจุดดังนี้ \( a = [4,6] ,b = [8,8], c = [4,8] \)
และสมการ Hyperplane
นำเอา a,b,c แทนเข้าไปในสมการ Hyperplane ได้ผลดังนี้
สังเกตุเครื่องหมายของผลลัพธ์ของสมการหลังจากผ่านข้อมูลจุด a,b,c ออกมาเป็น \( -, + ,0 \) ตามลำดับ เมื่อนำไป plot
จากรูปที่ 1 แสดงให้เห็นว่า ถ้าค่าของสมการ Hyperplane ออกมาน้อยกว่า 0 จุดอยู่ใต้เส้น หากมากกว่า 0 จะอยู่เหนือเส้น และหากเท่ากับ 0 จะอยู่บนเส้น สรุปออกมาได้ดังรูปที่ 2
พิจารณารูปที่ 2 ถ้าหากถูกขอให้พิจารณาความมั่นใจในการแยกจุด C ออกจากจุด A และการแยกจุด B ออกจากจุด A น่าจะได้คำตอบว่า การแยกจุด C ออกจากจุด A จะให้ความมั่นใจสูงกว่า ทั้งนี้เพราะเรามองได้ชัดว่าระยะห่างระหว่างจุด C กับ Hyperplane มากกว่ากว่าจุด B
เราทราบแล้วว่าการใช้ สมการ hyperplane ร่วมกับ hypothesis function สามารถใช้แบ่งกลุ่มข้อมูลได้ คำถามที่เกิดขึ้นคือหากเรามี hyperplane มากกว่า 1 hyperplane แล้ว เราควรเลือก hyperplane ไหนที่เหมาะกับ data set ที่มีอยู่
ระยะทางระหว่างจุดกับเส้นตรง สามารถหาได้จากสมการ [1]
รูปแบบของสมการ vector
เราสามารถทดสอบได้โดยการนำเอา data set มาทดสอบกับ hyperplane ทุก hyperplane ซึ่งจะได้ค่าของ hyperplane ออกมา เลือกค่าที่น้อยที่สุดของแต่ละ hyperplane มาเทียบกัน แล้วเลือก hyperplane ที่ให้ค่ามากที่สุดเป็น hyperplane ที่เหมาะสม
ดูตัวอย่าง
\( \bf data set = [1, 3], [2, 5], [2, 7], [4, 4], [4, 6], [7, 5], [8, 3], [4, 8], [ 4, 10], [ 7, 10], [7, 9], [8, 8], [9, 7], [10, 10]\)
สมการ hyperplane :
\( \bf \large \beta_1 = (0.5,1.0) \cdot (x_1,x_2) - 10 \)
\( \bf \large \beta_2 = (0.3,1.0) \cdot (x_1,x_2) - 8 \)
\( \bf \large \beta_3 = (0.7,1.0) \cdot (x_1,x_2)- 10 \)
ค่า minimum ของแต่ละ hyperplane :
\( \bf \large \beta_1 = 0.00 \)
\( \bf \large \beta_2 = 0.38 \)
\( \bf \large \beta_3 = 0.08 \)
ได้ว่าสมการ hyperplane ที่สองให้ค่าสูงสุดจากค่า margin ที่มากที่สุดในสามค่าที่ได้ ดังนั้น hyperplane ที่สองจึงเป็น hyperplane ที่เหมาะสมที่สุด
เอกสารอ้างอิง
[1] https://smarter-machine.blogspot.com/2018/07/perpendicular-distance-from-point-to.html
และสมการ Hyperplane
\[\bf \hat{w} \cdot \hat{x} = 0 \]
\[ \hat{w}= \begin{bmatrix}0.5 &1.0 &-10.0 \end{bmatrix} \]
\[ \hat{x} = \begin{bmatrix}x_1 \\ x_2 \\ 1 \end{bmatrix} \]
นำเอา a,b,c แทนเข้าไปในสมการ Hyperplane ได้ผลดังนี้
| a = [4,6] | \(\begin{bmatrix}0.5 &1.0&-10.0\end{bmatrix} \cdot \begin{bmatrix}4 \\6\\1\end{bmatrix} = -4 \) |
| b = [8,8] | \( \begin{bmatrix}0.5&1.0&-10.0\end{bmatrix} \cdot \begin{bmatrix}8\\8\\1 \end{bmatrix}= 2 \) |
| c = [4,8] | \( \begin{bmatrix}0.5&1.0&-10.0\end{bmatrix} \cdot \begin{bmatrix}4\\8\\1 \end{bmatrix} = 0 \) |
สังเกตุเครื่องหมายของผลลัพธ์ของสมการหลังจากผ่านข้อมูลจุด a,b,c ออกมาเป็น \( -, + ,0 \) ตามลำดับ เมื่อนำไป plot
 |
| รูปที่ 1 |
จากรูปที่ 1 แสดงให้เห็นว่า ถ้าค่าของสมการ Hyperplane ออกมาน้อยกว่า 0 จุดอยู่ใต้เส้น หากมากกว่า 0 จะอยู่เหนือเส้น และหากเท่ากับ 0 จะอยู่บนเส้น สรุปออกมาได้ดังรูปที่ 2
 |
| รูปที่ 2 |
เราทราบแล้วว่าการใช้ สมการ hyperplane ร่วมกับ hypothesis function สามารถใช้แบ่งกลุ่มข้อมูลได้ คำถามที่เกิดขึ้นคือหากเรามี hyperplane มากกว่า 1 hyperplane แล้ว เราควรเลือก hyperplane ไหนที่เหมาะกับ data set ที่มีอยู่
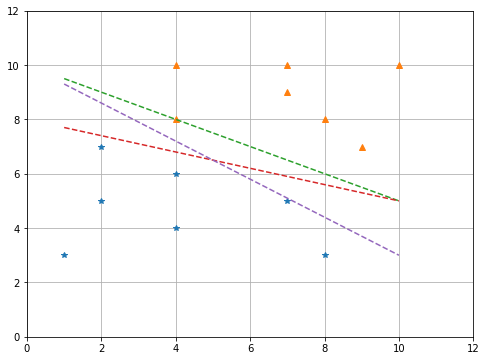 |
| รูปที่ 3 |
ระยะทางระหว่างจุดกับเส้นตรง สามารถหาได้จากสมการ [1]
\[ \bf D = \frac{ax_1+bx_2+c}{\sqrt[2]{a^2+b^2}} \dashrightarrow (1) \]
รูปแบบของสมการ vector
\[ \bf D = \frac{\vec w \cdot \vec x +b }{\mid\mid \vec w \mid\mid} \dashrightarrow (2)\]
พิจารณาสมการ (2) จะเห็นว่า เมื่อนำค่าจาก data set มาแทนค่าลงสมการที่ละจุดไปเรื่อย ๆ ค่าที่ออกมานั้นก็คือระยะห่างระหว่างจุดที่เป็นตัวแทนของข้อมูลกับเส้น hyperplane (การนำเอาค่า \(\mid\mid w \mid\mid \) ซึ่งเป็นค่าคงที่ไปหารก็คือการทำ normalize ค่าของระยะทาง) ค่านี้ต่อไปจะเรียกว่า "margin"
หากเปรียบการหา hyperplane เป็นการสร้างถนนคั่นระหว่างข้อมูลสองกลุ่ม เราก็กำลังพยายามสร้างถนนให้กว้างที่สุดเท่าที่จะทำได้ แต่ต้องไม่กว้างเกินไปจนไปทับอยู่บนตัวข้อมูล
หากเปรียบการหา hyperplane เป็นการสร้างถนนคั่นระหว่างข้อมูลสองกลุ่ม เราก็กำลังพยายามสร้างถนนให้กว้างที่สุดเท่าที่จะทำได้ แต่ต้องไม่กว้างเกินไปจนไปทับอยู่บนตัวข้อมูล
เราสามารถทดสอบได้โดยการนำเอา data set มาทดสอบกับ hyperplane ทุก hyperplane ซึ่งจะได้ค่าของ hyperplane ออกมา เลือกค่าที่น้อยที่สุดของแต่ละ hyperplane มาเทียบกัน แล้วเลือก hyperplane ที่ให้ค่ามากที่สุดเป็น hyperplane ที่เหมาะสม
 |
| รูปที่ 4 |
ดูตัวอย่าง
\( \bf data set = [1, 3], [2, 5], [2, 7], [4, 4], [4, 6], [7, 5], [8, 3], [4, 8], [ 4, 10], [ 7, 10], [7, 9], [8, 8], [9, 7], [10, 10]\)
สมการ hyperplane :
\( \bf \large \beta_1 = (0.5,1.0) \cdot (x_1,x_2) - 10 \)
\( \bf \large \beta_2 = (0.3,1.0) \cdot (x_1,x_2) - 8 \)
\( \bf \large \beta_3 = (0.7,1.0) \cdot (x_1,x_2)- 10 \)
ค่า minimum ของแต่ละ hyperplane :
\( \bf \large \beta_1 = 0.00 \)
\( \bf \large \beta_2 = 0.38 \)
\( \bf \large \beta_3 = 0.08 \)
ได้ว่าสมการ hyperplane ที่สองให้ค่าสูงสุดจากค่า margin ที่มากที่สุดในสามค่าที่ได้ ดังนั้น hyperplane ที่สองจึงเป็น hyperplane ที่เหมาะสมที่สุด
 |
| hyperplane ที่ 1 และที่ 3 ให้ผลของการแบ่งข้อมูลได้ไม่ค่อยดีนัก จะเห็นว่ามีข้อมูลบางส่วนไปอยู่บน hyperplane |
 |
| hyperplane ที่สองให้ภาพการแบ่งกลุ่มข้อมูลที่ดีกว่า ไม่มีข้อมูลไปอยู่บน hyperplane |
 |
| แสดง hyperplane ที่เหมาะสมพร้อม margin |
Hyperplane ที่เหมาะสมควรให้ค่า margin ที่มากที่สุดเมื่อแทนที่ด้วย data set ที่มีอยู่
\[ \bf \beta_i = \hat{w}_i \cdot \hat{x}_i, i = 1,2,3,..,n \]
\[ \bf B = min(\beta_i)\]
เลือก hyperplane ที่ให้ค่า \( max(B_i)\)
เอกสารอ้างอิง
[1] https://smarter-machine.blogspot.com/2018/07/perpendicular-distance-from-point-to.html
ความคิดเห็น
แสดงความคิดเห็น